|
|
Двигаемся поэтапно, с самого начала.
1. Никаких виртуальных функций (пока что)
Используем struct вместо class чтобы каждый раз не писать public. В нашем примере не будет никаких приватных членов класса, а в остальном все тоже самое:
|
|
struct Parent { void f() {} // (1) }; struct Child : public Parent { void f() {} // (2) }; |
Функция f() переопределена в дочернем классе Child (overriding, не путать с overloading). Вызов функций:
|
|
Parent* p = new Parent; p->f(); // будет вызвана (1) Child* p = new Child; p->f(); // будет вызвана (2) |
Пока никаких неожиданностей нет — все работает как должно.
Замечу, что если в дочернем классе не будет функции (2), то будет вызвана функция (1) родительского класса. Это происходит потому, что Child хранит гены родителя Parent и в силу наследования имеет доступ ко всем полям родительского класса. Но это так, к слову.
2. Все еще никаких виртуальных функций
Сделаем странную вещь — присвоим указателю на объект родительского класса объект производного класса и поразмышляем над тем, что получилось.
|
|
Parent* p = new Child; p->f(); // будет вызвана (1) !!! |
Указатель на Parent, а объект Child… нет ли здесь несоответствия или противоречия?
Рассуждаем так. Указатель на объект класса — это не просто адрес в памяти. Когда мы имеем дело с классами, фактически имеем набор указателей на все поля и функции класса — это если упростить (а упрощать мы любим). Выше я говорил, что Child хранит «гены» родителя Parent, в нашем случае — функцию (1) родительского класса. Поэтому указатель на Parent находит в Child то, про что он знает — отсылку на свою собственную функцию (1).
При этом родительский класс не знает абсолютно ничего про остальные поля и функции, которые эксклюзивно находятся в Child. И если последний содержит например функцию g(), то компиляция p->g() даст ошибку.
В ситуации наоборот
|
|
Child* p = new Parent; // ошибка компиляции |
Указатель захочет сослаться на поля, которые есть только в Child, но в объекте Parent их быть не может!
3. Подозрительная конструкция
Поехали дальше. Возникает закономерный вопрос: зачем вообще нужна такая конструкция
когда все прекрасно работает и без нее? Следствие, которое ведут Колобки, знает: встретили такую запись — значит где-то поблизости виртуальная функция (и может быть не одна).
И наоборот — видите объявление виртуальной функции, ищите в коде конструкцию подобного вида: она обязательно будет, потому что без нее объявлять функцию виртуальной нет смысла.
Поэтому смотрим пока на то что «нет смысла», а потом переходим к заключительному полноценному примеру.
4. Бессмысленная виртуальная функция
|
|
struct Parent { virtual void f() {} // (1) }; struct Child : public Parent { void f() override {} // (2) }; |
Теперь функция f() стала виртуальной. Заведите хорошую привычку дописывать override в дочерних классах, чтобы во-первых было понятно что функция виртуальная (это здесь все видно, а если вы копаетесь в многочисленных листингах?), и во-вторых это страхует вас от ошибки в сигнатуре функции — без override компилятор все пропустит, но будет считать f() в дочернем классе уже не виртуальной, а с override — предупредит.
Повторяем наш эксперимент с самого начала.
|
|
Parent* p = new Parent; p->f(); // будет вызвана (1) Child* p = new Child; p->f(); // будет вызвана (2) |
Вы заметили какую — нибудь разницу по сравнению с первым сценарием без виртуальных функций? И я тоже нет.
Давайте быстро забудем про это бессмысленное применение virtual и перейдем к нашей сакраментальной конструкции, и тут она уже заиграет в полную силу.
5. Складываем все вместе
Объявление класса с виртуальными функциями:
|
|
struct Parent { virtual void f() {} // (1) }; struct Child : public Parent { void f() override {} // (2) }; |
Действие:
|
|
Parent* p = new Child; p->f(); // будет вызвана (2) !!! |
У меня для вас новость: объект родительского класса каким-то образом узнал про функцию в дочернем классе и вызвал именно ее. Как он это сделал?
Сейчас самое главное — не погрузиться в дебри новых понятий и не потерять прозрачность повествования. Новое понятие — это таблица виртуальных функций vtable класса Parent, которая содержит указатели на виртуальные функции. Отныне все вызовы виртуальных функций будут происходить не через указатель класса Parent* p, а через посредника — таблицу vtable.
Принципиально важным является то, что содержимое этой таблицы не задается жестко во время компиляции, а может меняться по ходу выполнения программы (это то, что вас на собеседовании спрашивали про позднее связывание или dynamic binding). Если мы поймем, как и когда эта таблица заполняется и меняется, мы поймем все про виртуальные функции. Поехали!
6. Gdb, vtbl
Ехать будем с помощью отладчика gdb — это наиболее удобный способ посмотреть расположение vtable и виртуальных функций в памяти. Поменяем наш пример, чтобы с отладчиком было удобнее работать:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
#include <iostream> using namespace std; class Base { public: virtual void base_and_derived(void) { cout << "Base::f" << endl; } virtual void base(void) { cout << "Base::fonly" << endl; } }; class Derived : public Base { public: void base_and_derived(void) override { cout << "Derived::f" << endl; } virtual void derived(void) { cout << "Derived::v" << endl; } }; int main (int argh, char *argv[]) { Base* b = new Base(); Derived* d = new Derived(); b = d; return 0; } |
Компилируемся, запускаем отладку:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
(gdb) b main Breakpoint 1 at 0x11dd: file faddr.cpp, line 21. (gdb) run Starting program: /home/***/faddr [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1". Breakpoint 1, main (argh=1, argv=0x7fffffffdfc8) at faddr.cpp:21 21 b = new Base(); (gdb) n 23 d = new Derived(); (gdb) n 24 b = d; (gdb) info vtbl b vtable for 'Base' @ 0x555555557d50 (subobject @ 0x55555556aeb0): [0]: 0x5555555552a0 <Base::base_and_derived()> [1]: 0x5555555552de <Base::base()> (gdb) info vtbl d vtable for 'Derived' @ 0x555555557d28 (subobject @ 0x55555556aed0): [0]: 0x55555555531c <Derived::base_and_derived()> [1]: 0x5555555552de <Base::base()> [2]: 0x55555555535a <Derived::derived()> |
Замечу что b = d еще не выполнялось: мы остановились до этой строчки.
Для успокоения души проверим адреса, которые нам выдал отладчик, например для b:
|
|
(gdb) x /2xg 0x555555557d50 0x555555557d50 <_ZTV4Base+16>: 0x00005555555552a0 0x00005555555552de |
Все в порядке, vtable содержит адреса Base::base_and_derived() и Base::base() (доверяй, но проверяй!)
Теперь посмотрим на таблицы, на какие виртуальные функции они указывают. С классом Base все понятно, это пара собственных виртуальных функций base_and_derived(), base(). С дочерним классом Derived немного интереснее: его таблица содержит переопределенную виртуальную функцию базового класса base_and_derived(), собственно виртуальную функцию base() которая принадлежит базовому классу (родитель!) и собственная виртуальная derived().
Само собой, адреса виртуальных таблиц 0x555555557d50 и 0x555555557d28 различаются, поскольку у каждого класса (не экземпляра класса!) своя виртуальная таблица. Это замечание пригодится нам прямо сейчас.
Продолжаем программу и выполняем наше легендарное присвоение указателя производного класса указателю базового класса:
|
|
(gdb) n 26 return 0; (gdb) info vtbl b vtable for 'Base' @ 0x555555557d28 (subobject @ 0x55555556aed0): [0]: 0x55555555531c <Derived::base_and_derived()> [1]: 0x5555555552de <Base::base()> (gdb) info vtbl d vtable for 'Derived' @ 0x555555557d28 (subobject @ 0x55555556aed0): [0]: 0x55555555531c <Derived::base_and_derived()> [1]: 0x5555555552de <Base::base()> [2]: 0x55555555535a <Derived::derived()> |
Произошли существенные изменения, и главное из них — мы фактически потеряли виртуальную таблицу базового класса (что еще можно было ожидать от присваивания?) Точнее, базовый и производный класс сейчас содержат только одну виртуальную таблицу расположенную по адресу 0x555555557d28, которая по сути таблица класса Derived оставленная без изменений —.
Поскольку класс Base теперь пользуется виртуальной таблицей класса Derived, предыдущая запись
0x5555555552a0 <Base::base_and_derived()>
Поменялась на запись
0x5555555552a0 <Base::base_and_derived()>
какой она и была для Derived раньше.
Это означает: все вызовы виртуальной функции base_and_derived выполненные с помощью указателя b->base_and_derived() приведут не к вызову виртуальной функции базового класса (как можно было ожидать, ведь b — указатель на Base), а к вызову виртуальной функции произвольного класса.
Что и требовалось доказать.
7. Послесловие
Вот и все. Приведу пример, когда это бывает нужно в реальной жизни. Например, клиент знает только про класс Interface и пользуется им:
|
|
struct Interface { virtual int api() {} // client interface }; // то что ниже - клиенту знать не обязательно struct Implementation_1 : public Parent { int api() override {} // api version 1 }; struct Implementation_2 : public Parent { int api() override {} // api version 2 }; |
У нас есть возможность подсовывать различные варианты реализации интерфейса, оставляя клиента в неведении:
|
|
Interface* if; if = new Implementation_1; if->api(); // будет вызвана версия 1 api if = new Implementation_2; if->api(); // будет вызвана версия 2 api |
Этот пример можно воспринимать по другому: например, Implementation_1 это боевая реализация, а Implementation_2 это mock заглушка для тестирования. Или Interface это класс прокси или адаптера. В общем все шаблоны C++ которые только существуют базируются на этой записи:
и это все, что вам нужно знать про полиморфизм в C++.
Понимаю, тема несколько выбивается из ряда… но разнообразие прекрасно, полезно и бодрит, поэтому продолжаем. В последние два с половиной года я был сильно погружен коммерческую разработку на C++ , мой стол набитый комплектацией простаивал без дела, и вот пришло время размяться на аналоговом поле.
На самом деле микрофонный усилитель — это не просто так, а часть моего проекта, который я завершу — когда нибудь, надеюсь. Задача усилителя — завести голос с микрофона гарнитуры на АЦП STM32. Определенное время я развлекался, знакомясь с ужасными схемотехническими решениями, которые кочуют с сайта на сайт (высокоимпедансный микрофон на вход схемы с общим эмиттером), и решил дать простое решение с подробными разъяснениями (фокус с последующим разоблачением).
Итак, смотрим чертеж.
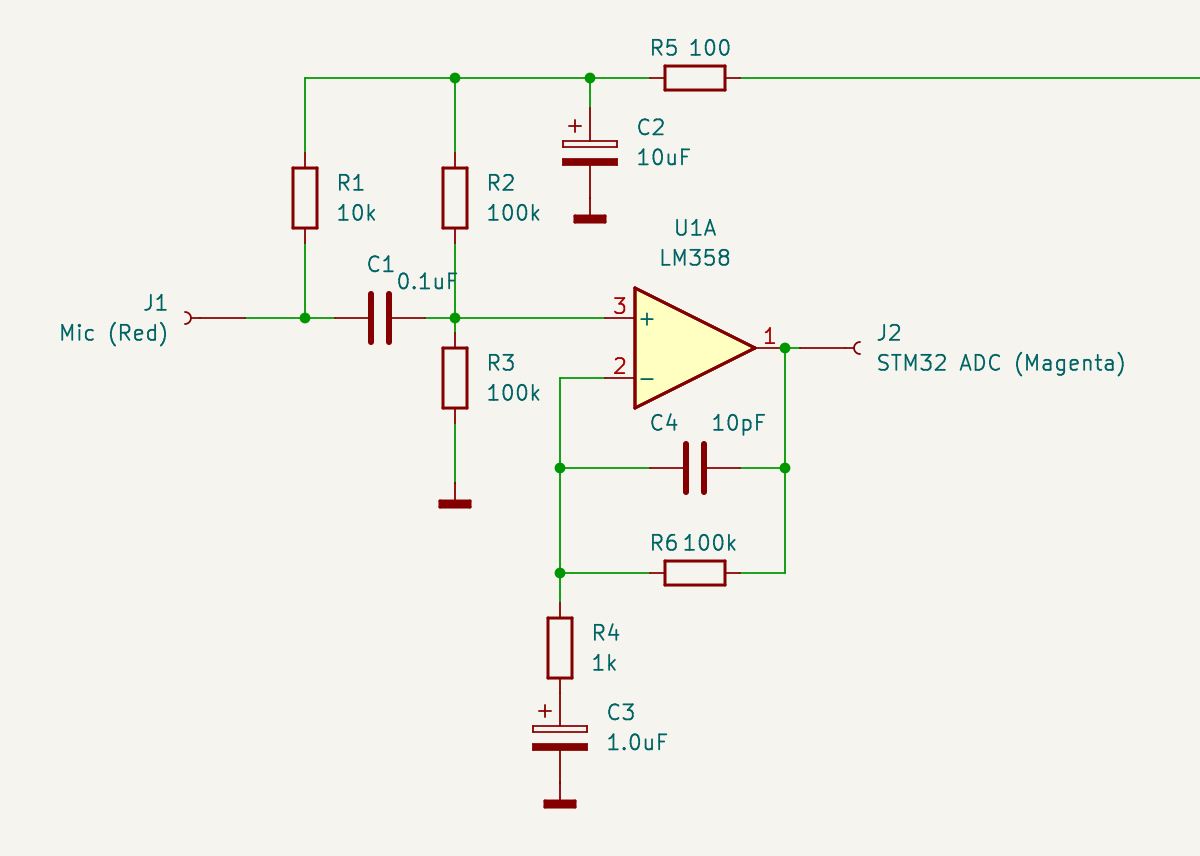 Микрофонный усилитель на LM358 / Microphone amplifier LM358 Слева подключаем микрофон, справа подаем выход усилителя на АЦП микроконтроллера. Пусть обозначения цветов вас не смущают — это маркировка проводов в моем монтаже.
Начинаем с микрофона. В гарнитуре он или электретный, или конденсаторный. И в том и другом случае на него нужно подать питание, что делает резистор R1, обеспечивая положительное смещение. Также и в том и другом случае микрофон имеет высокий импеданс, поэтому нагрузочный каскад должен иметь высокое входное сопротивление. Ходят легенды, что в микрофоны встраивают полевой транзистор, который обеспечивает высокоомную нагрузку для него — благо что питание подавать все равно надо. Я специально разобрал такой один, но транзистор вероятно был настолько мал, что я его не нашел даже под лупой.
Поэтому пусть будет универсальное решение — вход нашего усилителя будет высокоомным, поэтому подаем сигнал с микрофона на (+) вход операционного усилителя — ОУ. И давайте примем, что сопротивление входа (+) ОУ будет бесконечным, поэтому входную нагрузку будут определять параллельно включенные R2 и R3 (да — да, вы не ослышались — для сигнала что питание что земля все едино, поэтому микрофон получает нагрузку 50 кОм).
Лирическое отступление — почему на (+), а не на (-)? Ведь входы ОУ равноценны и образуют дифференциальный транзисторный каскад. Все дело в отрицательной обратной связи через R6, благодаря которой вход (+) становится высокоомным. Как это работает — рассказал на примере эмиттерного повторителя .
Давайте сразу про обратную связь. Она весьма двулична и ведет себя по-разному по постоянному и переменному току. По постоянному току играет R6 (и в этом варианте он вообще не нужен — мы могли бы накоротко замкнуть выход ОУ и вход (-)). Обратная связь получается 100 — процентной, поэтому коэффициент усиления каскада по постоянному току — единица, и средняя точка, которую устанавливает делитель R2/R3, будет такой же на выходе операционника, то есть — половина напряжения питания.
Теперь про обратную связь по переменному току. Здесь играет конденсатор C3, который закорачивает нижний конец резистора R4 на землю, в результате чего в цепи обратной связи появляется делитель R6/R4. Тут уже резистор R6 выполняет свою роль и совместно с R4 устанавливает коэффициент усиления каскада по переменному току, равный 100.
Конденсатор C4 давит усиление на высоких частотах, что лишает широкополосный LM358 возможности самовозбудиться на высоких частотах (вполне реальная перспектива, если фазовый сдвиг в цепи обратной связи получится другим нежели чем 180).
Поскольку режимы по постоянному току для микрофона и входа (+) ОУ — разные, изолируем эти цепи конденсатором C1. Надеюсь, не надо объяснять, что он проницаем для входного сигнала, и неожиданно маленькая емкость — 0.1 мкф совсем не большое препятствие, потому что опять таки — вход высокоомный.
Как вы наверное догадались, линия в верхней части, уходящая вдаль направо — это питание 3.3 В. Столько я рассчитываю получить с USB смартфона (ну вот, проговорился про еще про один кусок будущего проекта).
Для LM358 такое напряжение — нормально. Заметим, что выходной сигнал будет меняться не относительно земли (разделительного конденсатора на выходе ОУ нет), а между землей и 3.3 В — что АЦП и надо.
Для чего нужна цепочка R5C2? Практикующие инженеры знают, что мусор в цепях питания — обычное дело. На чувствительном входе каскада ОУ он нам совсем не нужен, и поэтому фильтр R5C2 будет прибивать все что по частоте выше постоянного тока (в идеале).
Пара электролит — керамика для сброса мусора на землю также стоит в правой части, которая не видна. Зачем керамический конденсатор маленькой емкости в параллель с электролитическим? Последние имеют неприятное свойство — паразитную индуктивность. Поэтому с ростом частоты они будут не очень хорошим конденсатором.

На макетке операционник в левой части. Особо зоркие могут заприметить транзистор в правой части — не обращайте на нее внимание, это очередной кусок проекта (который надо полностью поменять).
В результате экспериментов выяснилось, что усилитель держит неплохую полосу от 100 Гц до 10 кГц и негромких песен вполне достаточно до раскачки выхода от 0.5 В до 2.5 В.
When using numpy at the beginning of a project we don’t think about performance. This is because it is more important for us to get solution that works. And only then, with real data, observing how our computer begins to slow down, we have to find answer on how to avoid this. And then we remember the GPU inside our computer and think: can it help us?
Yes, sure. PyTorch can utilize GPU and perform all computations on it. PyTorch uses Tensor primitives like numpy arrays. Unlike numpy, once declared tensors reside on GPU, and are calculated on it. Due to a lot of the parallel working GPU inits, computing performance arises dramatically.
We will take the matrix multiplication algorithm for the example.
First, let’s make sure the multiplication computations are performed correctly.
|
|
import numpy as np a = np.array([[1,2],[3,4]]) b = np.array([[5,6],[7,8]]) print(a @ b) |
Output:
Everything is as expected.
Now, tensor comes into play. At this point, all the necessary modules and drivers have already been installed:
|
|
import torch print("Cuda is available" if torch.cuda.is_available() else "Cpu only available" ) |
Output:
Let’s allow PyTorch to multiply matricies:
|
|
ta = torch.from_numpy(a) tb = torch.from_numpy(b) print(torch.matmul(ta, tb)) |
Output:
|
|
tensor([[19, 22], [43, 50]]) |
The result is the same as for the numpy.
Take a larger matrices and see how much time it takes to calculate in each of the three modes:
1) PyTorch in «cpu» (numpy — like) CPU only mode
2) PyTorch in «cuda» (GPU) mode
3) Numpy CPU mode
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import datetime as dt dtype = torch.float M = 100 def calc(device): a = torch.rand(M, M, device=device, dtype=dtype) b = torch.rand(M, M, device=device, dtype=dtype) n1=dt.datetime.now() torch.matmul(a, b).size() n2=dt.datetime.now() print(device, '\t', M, n2-n1) a = np.random.rand(M, M).astype('f') b = np.random.rand(M, M).astype('f') n1=dt.datetime.now() np.matmul(a, b).size n2=dt.datetime.now() print("numpy", '\t', M, n2-n1) calc(torch.device("cpu")) calc(torch.device("cuda")) |
Output for M=100
|
|
numpy 100 0:00:00.000190 cpu 100 0:00:00.006382 cuda 100 0:00:00.017093 |
Output for M=1000
|
|
numpy 1000 0:00:00.014212 cpu 1000 0:00:00.064719 cuda 1000 0:00:00.014513 |
Output for M=10000
|
|
numpy 10000 0:00:12.415283 cpu 10000 0:00:12.241426 cuda 10000 0:00:00.036787 |
For small matrices (M=100) numpy looks like a performance champion. Even torch in cpu mode loses to it. The worst results are observed for the GPU.
For a medium-sized matrices (M=1000) the results are leveled out. Numpy and torch in cpu mode are the same and only torch in gpu mode is far behind.
At the moment, everything looks sad for GPU. It makes a real breakthrough for large-sized (M=10000) matrices. Here the gap in execution speed is huge: 37 milliseconds for GPU versus 12 seconds for numpy.
Simultaneous computing is good
Когда люди начали создавать компьютеры, сравнение с аналогичной продукцией живой природы не заставило себя ждать. Все (за редким исключением) сошлись во мнении, что нейросистемы животных слишком сложны и медленны, чтобы быть достойными более глубокого изучения. Здесь под изучением я подразумеваю не биохимический анализ нейронов, а понимание уровня системы: по каким алгоритмам она работает и самое главное — почему было сделано именно так.
Печально, но на вопрос «почему так» судя по всему отвечать некому. Подробно об этом написано в замечательной книге Доккинза «Слепой часовщик», а если коротко — то не было никакого Главного конструктора, который создавал живые организмы в тиши своего кабинета. Эволюция за сотни миллионов лет сама сделала эту работу, непрерывно экспериментируя с мутациями, оставляя жизнеспособные решения и безжалостно уничтожая ошибочные. Нам осталось строить предположения, наблюдая конечный результат.
Читать дальше…
По сравнению с такими шустрыми средствами, как противорадиолокационные ракеты (Anti Radar Missile) беспилотник выглядит сущим недоразумением. Однако, это всего лишь следствие инерции мышления, когда на самом деле главный недостаток БЛА по сравнению с ракетой — низкая скорость, становится преимуществом в следующих случаях:
- нужно хорошенько рассмотреть цель;
- можно позволить себе прогуляться для того чтобы выбрать что-либо подходящее в качестве цели, и достаточно долго — скажем, в течение суток (барражирующий боеприпас);
- за счет низкой радиальной доплеровской скорости и скромного значения ЭПР можно стать малозаметным для обнаружения.
Читать дальше…
В статье маркеры визуальной системы автоматической посадки БЛА была описана обработка видео-данных реального времени для системы оптического типа — VBLS. Это была хоть и шустрая, сделанная на C++, но модель. Теперь, как было замечено в конце этой статьи, пришло время показать систему в боевом варианте, где обработка видеопотока параллелится в ПЛИС.
В данной системе для экспериментов я выбрал весьма удобную отладочную плату Zedboard. Чип Zynq-7000 основан на SoC архитектуре ARM+FPGA, однако на этом этапе функционал ARM использовать не будем и ограничиваемся работой только с ПЛИС. В качестве камеры выступает популярный модуль OV7670 разрешением 640х480 (хвала Алиэкспрессу!). Почему такое скромное разрешение? А потому что в Zedboard ресурсы ограничены, в частности критичным для нас является размер встроенной быстродействующей памяти BRAM (не путать с DDR). Результирующее видео выводится на дисплей через разъем VGA платы.
Читать дальше…
Визуальная автоматическая посадка БЛА может выполняться не только по характерным точкам местности, но и по специально подготовленным и известным изображениям — маркерам. Собственно сама стандартная разметка ВПП состоит из таких маркеров, только исторически они предназначались не для обработки компьютером, а для человека — пилота. Поэтому нет ничего удивительного в том, что искусственный интеллект дрона потребует учесть его интересы и установить те маркеры, с которыми ему удобнее работать )
 Стандартизированная разметка ВПП. Маркеры обозначают тип полосы, точку касания и отклонение от этой точки Из рисунка видно — создатели разметки ВПП позаботились о том, чтобы четко были видны торцы полосы, причем они выполнены в виде вытянутых в сторону борта линий, чтобы обеспечить хорошее различение под низкими углами места — тот же принцип, что и в разметке пешеходного перехода. Возможно, для системы визуального зрения автоматической посадки VBLS этот набор маркеров не является оптимальным. Поэтому я поработал с разными классами изображений, характеристики которых такие как спектральные и корреляционные функции, инвариантность к изменению системы координат и возможности различения на фоне местности могут быть использованы для обнаружения и определения относительного положения маркера.
Читать дальше…
Эта история конечно имеет свои универсальные черты. Это означает, что разработка любой отечественной военной техники, не попадающей под непосредственное внимание первых лиц, идет примерно схожим образом. С другой стороны, в каждом проекте есть свои, отличающиеся от других особенности, и поэтому каждый волен выбирать, как ему воспринять эту историю: еще раз убедиться в том, как она подкрепляет свой печальный опыт или оптимистично протестовать в противоположном случае 😎
Мой рассказ — об отечественном военном аэродромном пеленгаторе. Именно аэродромном, поскольку АРП другого назначения, в том числе для радиоразведки, поиска и спасения находятся за рамками моего повествования. Да и тема аэродромной радиопеленгации для меня самая близкая, в которой я работаю с 1983 года.
Читать дальше…
В предыдущей статье я рассказывал о том, как хорошо работать с микроконтроллерами STM32 без операционной системы. Однако может наступить момент, когда вам понадобится наладить взаимодействие с вашим МК по сети. Например, что-нибудь типа умного дома или передача отладочной и диагностической информации на web страницу. Наличие Ethernet интерфейса — это конечно сильный аргумент для того, чтобы бросить STM32 и перейти на полноценный ARM процессор под управлением Linux. Однако, этот аргумент парируется очень просто: на рынке есть компактные Ethernet модули, которые можно задействовать в наших STM32 проектах. Речь идет о чипах семейства W5500 WIZnet, на основе которых эти модули и собраны. Добавляем к нашему проекту этот модуль (хвала Али Экспрессу, как обычно!), и получаем функциональность Ethernet в МК STM32.
Поскольку в этом эксперименте я использовал макетную плату без пайки, все стало выглядеть очень симпатично (по сравнению с предыдущими экспериментами). Поэтому не стыдно выложить фото этой сборки:
 Микроконтроллер STM32F103 и модуль Ethernet W5500 в сборе Работать с модулем W5500 — это сущий ад. В нем куча регистров, в которые нужно заносить и считывать информацию. Когда я раскрыл мануал этого чипа, то первое что я сделал — это сразу закрыл его и начал искать библиотеку, в которой вся эта регистровая часть уже реализована и которая предоставляет такие привычные и понятные интерфейсы: socket(), listen() и так далее. И я ее нашел.
Как работать с библиотекой я расскажу дальше, а пока поработаем с нашим фото.
Пройдемся по макетке слева направо и посмотрим, что я там разместил.
Макетная сборка
Модуль W5500
Слева, как вы уже догадались, Ethernet модуль W5500. В этом варианте исполнения его пины смотрят вниз, что удобно для размещения на макетной плате. Есть вариант и пинами вверх, что будет удобно если вы решите просто соединять контакты напрямую кабелями. Собственно чип W5500 распаян под зеленой платкой, из-за чего создается впечатление что кроме Ethernet разъема больше ничего нет. На самом деле это не так. Чип берет на себя всю работу по поддержке сетевых протоколов, а работать с ним нужно по интерфейсу SPI. Поэтому красные и темные проводки — это и есть соединения SPI с микроконтроллером.
Кто уже работал с SPI, сейчас испытывают небольшой диссонанс. Этот протокол вообще-то говоря принято использовать для внутриплатных соединений, и выводить его наружу считается моветоном. Пришлось поступиться принципами ради демонстрационных целей, потому что нужна скорость, которую другие популярные интерфейсы — I2C и UART обеспечивать не могут. Если же вы распаяете модуль W5500 на своей собственной плате, то правила поведения в приличном обществе будут соблюдены.
UART
Смещаем взгляд правее и видим вертикально воткнутую платку. Это адаптер UART-USB, с которым мы познакомились раньше. Его мы используем исключительно для отладочных целей, для того чтобы выводить сообщения нашей программы на экран PC.
От МК этой плате требуется только одна линия: Tx (отдаем строчки), которая на адаптере будет обозначаться уже как Rx (принимаем строчки). Ну и само собой кабель, который вы видите на торце платы, подключен к USB разъему PC.
Переключатель на плате устанавливаем в положение 3.3В: это будут уровни линий передачи данных, с которыми работает адаптер.
МК STM32F103 Blue Pill
По центру — наш микроконтроллер, плата МК STM32F103C8T6. Здесь неожиданностей нет, единственное я использовал компактную версию под названием Blue Pill. Есть еще Black Pill, Red Pill но честно говоря не знаю чем все они принципиально отличаются друг от друга. Работать будут все.
В комплекте с этими платами идут линейки пинов, которые я распаял снизу. Это позволяет вставить пины контроллера в макетную плату. Если вы используете Pill’ы в своих устройствах, запаивать пины нет необходимости — можно сразу паять соединения на ламели по краям платы. В нашей конфигурации используются контакты соответствующие UART1 и SPI2.
К разъему JTAG в торце платы МК как обычно подключен программатор/отладчик ST-LINK V2. Его мы видим сверху. Его место — также в USB разъеме PC.
USB разъем для электропитания не используется — напряжение подается непосредственно на пины МК.
Электропитание
На правой стороне макетной платы расположен весьма удобный модуль электропитания, который обеспечивает независимые напряжения 5В или 3.3 В по обеим линиям питания макетной платы (синие и красные линии). Своими пинами модуль ложится в аккурат на эти линии, плюс к этому есть возможность подключиться еще сверху. Входное напряжение для модуля — 12В.
Модуль питания сконфигурирован джамперами на выходное напряжение 3.3В, отбор питания идет по внешним линиям модулями W5500 и МК STM32, которым требуется 3.3В. На фото видны эти желтые и коричневые короткие перемычки, которые идут рядом.
Нюанс: вы пожете подключить к МК вместо 3.3В 5В к соответствующему (другому естественно!) контакту. Эти 5В будут преобразованы в 3.3В.
Внимание! Не подключайте к плате внешнее питание 3.3В и 5В от USB одновременно. Можете потерять МК ) Также по этой причине провод +5В для JTAG от USB PC болтается в воздухе, как может заметить внимательный читатель )
Модуль UART требует электропитание 5В, которое мы обеспечиваем внешним проводком который подключается к пину +5В модуля питания. Есть подозрение, что он прекрасно будет работать и без этого проводка от USB, когда тот подключен (и работает на самом деле).
Ситуация когда к одной цепи питания модуля подключаются два источника питания — не совсем здоровая. Картинку портит поступающие 5В от USB, которые преобразуются в 3.3В и эта цепь потенциально может конфликтовать с внешней линией питания 3.3В. В таких случаях обычно ставят диод Шоттки, который защищает цепи питания 3.3В от реверсного тока. Будем надеяться, что так оно и есть )
Зачем вообще нужен модуль питания, если раньше мы прекрасно запитывали микроконтроллер от USB? Не забываем, что теперь у нас появился серьезный потребитель по напряжению 3.3В — это чип W5500, который не в лучшие для нас моменты готов принять до 185мА. Внутренний преобразователь уровня 5/3.3В микроконтроллера на такой подвиг не способен, если нам в голову придет мысль взять напряжение 3.3В оттуда.
Конфигурация
Как и раньше, для создания проекта воспользуемся услугами STM32CubeMX. По традиции создаем проект на основе Makefile, чтобы не городить огород с визуальными системами разработки (помните наш проект hardcore? Только Makefile и vim!). Как обычно, включаем пункт Debug:Serial Wire в меню SYS, чтобы иметь возможность прошивки и отладки. Сразу включатся пины PA13, PA14: через них STLINK будет общаться с МК.
Осталось сконфигурировать интерфейсы и все. Включаем USART1: Mode Asynchronous (Куб задействует пины PA9, PA10) и включаем SPI2: Mode Full-Duplex Master. На вкладке конфигурации для SPI2 нужно будет подправить параметр Prescaler: установить его в значение 4. Напоминаю еще раз, что UART нужен только для отладки, чтобы получать на нашем компе логи из программы контроллера.
Почему SPI2 а не SPI1? Так было в библиотеке поддержки чипа W5500, я не стал менять интерфейс. Видимо, разработчикам было удобно работать с пинами именно с этой стороны модуля микроконтроллера ) В нашем случае Куб выдаст для SPI пины PB13 — PB15.
Нам еще понадобится управлять пином PB12 как выходным (забегая вперед — библиотека использует его для включения чипа W5500). Поэтому кликаем на него и делаем GPIO_Output. И точно также, сразу делаем выходным пин PC13: к нему подключен светодиод МК, и грех не воспользоваться возможностью поморгать светодиодом в нужных местах.
Создаем проект и переходим к следующему шагу.
Соединения
Поскольку распиновка модулей W5500 и UART-USB и так известна, а распиновку Blue Pill мы уже получили с помощью Куба, займемся соединениями. Работа приятная, медитативная, навевает мысли о тщете всего сущего, хорошо заниматься этим перед сном, глубокое погружение гарантировано 🙂
Начнем с модуля W5500. Все, что нам от него нужно — это цепи SPI и питания. С подключением питания все понятно — задействуем цепи 3.3В и GND, самое главное — правильно соединить линии интерфейса SPI. Поскольку на модуле нет нумерации пинов, на схеме соединений слева будем указывать SPI обозначение пина по версии W5500, справа — номер пина и SPI обозначение по версии Куба:
 Распиновка модуля W5500 |
|
|
W5500 STM32 MOSI ---------- MOSI PB15 MISO ---------- MISO PB14 SCLK ---------- SCK PB13 SCNn ---------- GPIO PB12 |
|
Памятка по SPI:
- MISO — Master In, Slave Out: если мы в режиме мастер — принимаем данные, в режиме периферии — передаем;
- MOSI — Master Out, Slave In: в режиме мастер передаем данные, в режиме периферии — принимаем.
В нашей конфигурации W5500 будет периферийным модулем, который будет выбираться сигналом SCNn с МК. Поэтому по линии MISO данные будут идти от W5500 к МК, по линии MOSI — в противоположном направлении. Обратите внимание, что нет необходимости переполюсовки Tx/Rx как в UART: назначение вывода (вход или выход) меняется в зависимости от того, в каком режиме — Master или Slave работает модуль.
С модулем UART-USB все просто. Нужна только одна линия передачи данных:
|
|
UART-USB STM32 2 Rx ---------- Tx PA9 |
И в заключение — подключаем программатор/отладчик ST-LINK V2:
|
|
STLINK STM32 2 ----- SWDIO ----- 7 4 ----- SWCLK ----- 9 |
Цепь 3.3В остается неподключенной!
Не забудьте соединить «земли» всех модулей с землей модуля питания и подать 3.3В на модули W5500 и Blue Pill. Модуль UART-USB, как я говорил до этого, подключается к пину 5В модуля питания.
W5500 Library
Наконец наступил долгожданный момент — подключение библиотеки модуля W5500, чтобы с ним можно было работать вменяемым образом. Саму библиотеку можно скачать здесь. На самом деле, это не совсем библиотека, а набор файлов которые нужно включить в наш проект. Они точно также будут компилиться и собираться, как и наши собственные файлы. Поэтому по структуре это не library, а дополнительные к нашему проекту кусочки. Но я все равно буду называть это библиотекой — по существу. Кому нравится — могут называть это также драйвером; сама WizNet вообще использует наименование Library_Driver.
Подобные продукты третьих сторон я храню отдельно от своего проекта, потому как не нужно дублировать исходники в каждом отдельном проекте и тем более включать их в систему контроля версий. Для этого у меня специальная директория — /home/user/bin, куда и скачаем библиотеку WizNet она же драйвер W5500.
Распаковываем архив и меням имя на ioLibrary_Driver. Далее, нужно настроить библиотеку на определенную версию чипа. Для этого в файле Ethernet/wizchip_conf.h ищем строчку вида
|
|
#define _WIZCHIP_ W5500 // W5100, W5100S, W5200, W5300, W5500 |
И меняем W5500 на модель чипа, которая у вас в наличии. Само собой у меня менять ничего не пришлось.
Теперь нужно как-то интегрировать исходники библиотеки в наш проект. Это делается через Makefile. Добавляем в него строки следующим образом (будьте внимательны: показаны также существующие строки, чтобы вам было проще ориентироваться по make-файлу):
|
|
BUILD_DIR = build # путь к библиотеке пишем один раз IOLIB = /home/user/bin/ioLibrary_Driver/Ethernet |
|
|
Drivers/STM32F1xx_HAL_Driver/Src/stm32f1xx_hal_flash_ex.c \ Src/system_stm32f1xx.c \ # все что требуется включить в проект - эти три исходных файла $(IOLIB)/socket.c \ $(IOLIB)/wizchip_conf.c \ $(IOLIB)/W5500/w5500.c \ # наша оболочка к библиотеке, о ней - позже Src/tcp.c |
|
|
-IDrivers/CMSIS/Include \ # позаботимся о том, чтобы компилятор нашел header файлы библиотеки -I$(IOLIB) \ -I$(IOLIB)/W5500 |
Все достаточно просто, не правда ли? Наступил момент запуска библиотеки. Для этого ее нужно инициализировать и выполнить тестовый пример — запустить TCP сервер который будет принимать входящее соединение и отвечать чем-то в стиле «Hello World».
Software
Как вы наверное уже догадались, все это будет жить в файле tcp.c. Но вначале библиотеку нужно инициализировать. Код инициализации разместим в main.c, поскольку так ему будет проще доступаться к интерфейсным переменным.
Первым делом нужно приготовить для библиотеки наши callback функции, которые она будет дергать когда ей понадобится доступ к SPI для обмена с чипом WZ5500:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
/* USER CODE BEGIN PFP */ /* Private function prototypes -----------------------------------------------*/ // предоставляем библиотеке возможности: // включить модуль W5500 сигналом SCNn=0 void cs_sel() { HAL_GPIO_WritePin(GPIOB, GPIO_PIN_12, GPIO_PIN_RESET); //CS LOW } // выключить модуль W5500 сигналом SCNn=1 void cs_desel() { HAL_GPIO_WritePin(GPIOB, GPIO_PIN_12, GPIO_PIN_SET); //CS HIGH } // принять байт через SPI uint8_t spi_rb(void) { uint8_t rbuf; HAL_SPI_Receive(&hspi2, &rbuf, 1, 0xFFFFFFFF); return rbuf; } // передать байт через SPI void spi_wb(uint8_t b) { HAL_SPI_Transmit(&hspi2, &b, 1, 0xFFFFFFFF); } |
Теперь библиотеке нужно как-то сообщить о нашей проделанной работе. Регистрация наших callback-функций в библиотеке выполняется следующей парой строк:
|
|
reg_wizchip_cs_cbfunc(cs_sel, cs_desel); reg_wizchip_spi_cbfunc(spi_rb, spi_wb); |
Само собой, это уже вызовы функций библиотеки. Дальнейшая инициализация:
|
|
uint8_t bufSize[] = {2, 2, 2, 2}; wizchip_init(bufSize, bufSize); wiz_NetInfo netInfo = { .mac = {0x00, 0x08, 0xdc, 0xab, 0xcd, 0xef}, // MAC адрес .ip = {192, 168, 77, 6}, // IP адрес .sn = {255, 255, 255, 0}, // маска сети .gw = {192, 168, 77, 1}}; // адрес шлюза wizchip_setnetinfo(&netInfo); wizchip_getnetinfo(&netInfo); |
Обращаем внимание на то, что прямо здесь идут сетевые настройки модуля. В результате в структуре netInfo будет храниться вся сетевая информация, которую вы можете вывести на экран вашего компа через модуль UART-USB сразу после инициализации.
Ну а теперь можно вызывать нашу функцию tcp_server(), которая будет делать всю полезную работу. Функцию разместим в файле Src/tcp.c. Не забудем объявить ее в заголовке main.h:
|
|
/* USER CODE BEGIN Private defines */ void tcp_server(); |
Так уж и быть, выложу полное содержание tcp.c. Как все это работает, описал в комментах. Для тех, кто знаком с логикой создания входящих tcp соединений, трудностей не будет никаких.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
// Copyright nazim.ru // BeerWare License #include "main.h" #include "stm32f1xx_hal.h" // внимание: это никакой не системный файл, а входит в состав библиотеки W5500 #include "socket.h" #include <string.h> char msg[60]; // это будем посылать tcp клиенту, когда он к нам приконнектится const char MSG[] = "Hello World"; // простой tcp сервер. Данные не принимаем, только посылаем строчку Hello World. // вы можете самостоятельно дополнить функцию для получения данных от клиента void tcp_server() { uint8_t retVal, sockStatus; // а вот это как раз моя функция вывода сообщений через модуль UART-USB // если вместо -1 поставить число, она и его отобразит. // в недрах этой функции работающая строка будет // HAL_UART_Transmit(&huart1, (uint8_t*)buf, strlen(buf), 0xFFFF); trace(-1,"Try open socket\r\n"); // открываем сокет 0 как TCP_SOCKET, порт 5000 */ if((retVal = socket(0, Sn_MR_TCP, 5000, 0)) != 0) { trace(-1, "Error open socket\r\n"); return; } trace(-1,"Socket opened, try listen\r\n"); // устанавливаем сокет в режим LISTEN. Так будет создан tcp сервер if((retVal = listen(0)) != SOCK_OK) { trace(-1, "Error listen socket\r\n"); return; } trace(-1,"Socked listened, wait for input connection\r\n"); // ждем входящих соединений. здесь мы немножко крутимся в бесконечном цикле // и чтобы не заскучать одновременно мигаем светодиодом while((sockStatus = getSn_SR(0)) == SOCK_LISTEN) { HAL_Delay(200); HAL_GPIO_TogglePin(GPIOC, GPIO_PIN_13); } // раз мы попали сюда, значит выскочили из цикла. входящее соединение! trace(-1,"Input connection\r\n"); if((sockStatus = getSn_SR(0)) != SOCK_ESTABLISHED) { trace(-1, "Error socket status\r\n"); return; } // из сокета вытаскиваем информацию: кто к нам пришел, откуда // можете также отобразить инфу в трассировке uint8_t remoteIP[4]; uint16_t remotePort; getsockopt(0, SO_DESTIP, remoteIP); getsockopt(0, SO_DESTPORT, (uint8_t*)&remotePort); // посылаем клиенту приветствие и закрываем сокет if((retVal = send(0, (uint8_t*)MSG, strlen(MSG))) == (int16_t)strlen(MSG)) // нехорошо так писать код. TODO: добавить фигурные скобки даже для одной строчки ) trace(-1, "Msg sent\r\n"); else trace(-1, "Error socket send\r\n"); // закрываемся. когда нас снова вызовут, мы всегда готовы кработе disconnect(0); close(0); } |
Проверяем все это так. Соединяем патчкордом модуль W5500 и наш комп. Конфигурируем проводное соединение, у меня на PC Ubuntu это адрес 192.168.77.5 (заметьте, что это также адрес шлюза для W5500). С нашей машины пингуем модуль: ping 192.168.77.6, убеждаемся что пинги проходят.
Дальше, достаем швейцарский нож хакера — программу netcat, коннектимся к модулю:
и получаем в ответ долгожданное «Hello World», а в экране minicom наблюдаем логи, которые посылает нам trace через модуль UART-USB.
Некоторые размышления по структуре программы. В ожидании входящих соединений, МК видимо будет выполнять полезную работу. Например обрабатывать поток радиолокационных данных ) Возникает проблема одновременной поддержки двух процессов. В Linux среде это решается просто — системным вызовом select(), который может зависать на нескольких событиях. В STM32 Линукса нет, но зато для STM32 есть простая операционная система реального времени FreeRtos. И она умеет работать с потоками, то есть содержит простейший планировщик заданий. Даю наводку, а как вы ей распорядитесь — ваше дело )
Про прошивку МК и отладку я подробно написал в предыдущей статье. Поэтому здесь описание этих процессов опущено.
Возможно, вы очень хотели заняться чем-нибудь, что связано с чипами, прошивками, возможно даже использовать новые знания для домашних поделок — мало ли вещей, которые можно автоматизировать, начиная от контроллера солнечной батареи и заканчивая автоматом запуска бензоагрегата? При этом, не сильно погружаясь в особенности операционных систем Linux / Windows и не используя сильно избыточные платы, такие как Raspberry Pi, BeagleBoard и подобные. Тогда добро пожаловать сюда: здесь мы запускаем микроконтролллер STM32, чистый «bare metal», никакой операционки, железо на расстоянии вытянутой руки и богатая собственная периферия.
В данной статье мы покажем то, чего не хватает в других публикациях в инете: не погружаясь в детали, схватим весь процесс разработки, начиная от простейшей программы Hello World и заканчивая ее прошивкой в контроллер и отладкой. Ну и конечно, как дань традиции, помигать светодиодом — без этого Hello World для микроконтроллеров получится совсем не солидным.
В этой статье не будет длинных листингов кода, которыми так славятся ресурсы по STM32, и не будет утомляющих скриншотов STM32CubeMX. Все будем описывать текстом — емко и кратко.
Набираем инструменты
Нам понадобятся приложения:
- STM32CubeMX — конфигуратор;
- текстовый редактор, например vim (категорически рекомендую освоить его);
- ST-LINK, которое состоит из двух утилит: st-flash для прошивки STM32 и st-util для отладки, или точнее st-util это настоящий gdb сервер;
- комплект для кросс-компиляции arm-none-eabi.
Сразу примечание: берем кросс-компилятор именно с «none», поскольку опять таки bare metal и другие варианты типа arm-linux-eabi нам не подходят, потому как подразумевают наличие операционной системы со всем набором сопутствующих библиотек, которые у нас будут отсутствовать напрочь.
Теперь у вас есть первая самостоятельная работа — найти и поставить эти приложения. Дальше я предполагаю, что на десктопе у вас стоит Linux, и изложение будет идти именно в этом ключе. Впрочем и для Windows процедуры будут отличаться не сильно.
Вторая самостоятельная работа — приобретение оборудования (хвала Али Экспрессу!). Нам понадобятся:
- плата с микроконтроллером STM32F103;
- программатор и отладчик St Link V2, похожий на флешку;
- миниатюрная платка адаптера UART — USB.
Цена вопроса за все про все — около 500р, ждать не больше месяца.
Да, чуть не забыл: закажите еще набор проводков с окончаниями «мама»: их удобно надевать на пины плат, получится очень аккуратно.
Roadmap
Окинем взором поле предстоящей деятельности и наметим наши шаги в крупную клетку. Именно в крупную, поскольку как мы договорились, в детали сильно погружаться не будем. На определенном этапе отсутствие именно этой крупной клетки сильно мешало мне, когда я застревал в многостраничных мануалах — деревьях, за которыми не видно леса. А этот лес у нас получится следующим.
Первым делом мы начнем использовать STM32CubeMX. Куб — это конфигуратор, который создает все файлы проекта со своей структурой каталогов. Если мы с самого начала знаем чего хотим, запустить его можно только один раз и потом про него забыть. Проект будет создан, мы будем менять код в программе, но структура останется. Еще раз — Куб это не среда разработки, а скажем так генератор шаблонов. Тем не менее сгенерированный им проект — вполне рабочий.
Сразу скажу, что Куб умеет формировать проекты для IDE разных типов. Мы, как поклонники vim и хардкора, никакими IDE пользоваться не будем — зачем нам эти бестолковые графические прослойки, заслоняющие реализацию? Редактор и Makefile — вот и все что нам нужно.
После того как структура проекта создана, мы внесем в исходники нечто похожее на вывод Hello World: должно же быть и какое-то наше участие в проекте. Сильно заморачиваться не будем, от нас потребуется буквально пара строчек. Сразу назовем наш проект сочно и звучно — hardcore.
После этого проект готов. Запускаем make и компилируем его, в результате чего создастся директория build и там появятся интересующие нас файлы: hardcore.bin — прошивка и hardcore.elf — исполняемый файл, который ценен тем что содержит отладочную информацию.
Следующим этапом прошиваем микроконтролллер:
|
|
st-flash write build/hardcore.bin 0x08000000 |
и после этого наша программа начнет работать. Мигающий на плате светодиод мы увидим и так, а чтобы посмотреть на заветную строчку Hello World которую выдает наше приложение, на компе нужно будет запустить терминал (конечно, если вы не забыли подключить адаптер UART — USB):
Мы также можем начать отладку нашей программы — например, пройти ее пошагово, для этого запускаем st-util и потом отладчик arm-none-eabi-gdb.
Общая картина ясна, дело за подробностями.
Связи
Опишем как все это соединяется друг с другом, не забывая стыки железа и софта.
Во первых, нужно соединить программатор / отладчик St Link V2 (который я для краткости далее буду называть донглом) и плату микроконтроллера. Донглу нужно две линии — по одной, двунаправленной он будет передавать и принимать данные, по другой — выдавать сигнал синхронизации. Плюс земля и питание платы: это удобно, не нужно подключать к плате источник питания, оно будет от донгла через USB разъем компа.
В комплекте к донглу идет как раз четырехжильный кабель, которым мы и воспользуемся. Подключаться нужно к 20-пиновому JTAG разъему платы микроконтроллера. Схема подключения:
|
|
STLINK ST32 2 ----- SWDIO ----- 7 4 ----- SWCLK ----- 9 6 ----- +3.3V ----- 1 8 ----- GND ----- 20 |
Вставляем донгл в USB, и если мы все сделали правильно, на плате загорится светодиод питания, и — надо же! начнет мигать другой светодиод — кто-то за нас позаботился о прошивке тестовой программы. Ну ничего, мы ее все равно сотрем, когда будем записывать свою.
Если вы решили запитать плату STM32 от внешнего источника питания, контакт +3.3В подсоединять не нужно. И помните золотое правило: прежде чем подавать питание все «земляные» контакты должны быть уже соединены!
Проверим наличие связи с платой:
|
|
$ st-util st-util 1.4.0-41-ge147a8e 2018-08-01T19:12:57 INFO usb.c: -- exit_dfu_mode 2018-08-01T19:12:57 INFO common.c: Loading device parameters.... 2018-08-01T19:12:57 INFO common.c: Device connected is: F1 Medium-density device, id 0x20036410 2018-08-01T19:12:57 INFO common.c: SRAM size: 0x5000 bytes (20 KiB), Flash: 0x10000 bytes (64 KiB) in pages of 1024 bytes 2018-08-01T19:12:57 INFO gdb-server.c: Chip ID is 00000410, Core ID is 1ba01477. 2018-08-01T19:12:57 INFO gdb-server.c: Listening at *:4242... |
Если выходит сообщение такого типа, что устройство обнаружено, то все в порядке.
Мы использовали последовательную линию для работы с JTAG и нужно не забыть сказать об этом потом конфигуратору Куб, иначе никаких прошивок потом не получится. Сразу говорю — если вы попали на неправильный параметр, прошили плату и сбили эту настройку, это лечится длительным нажатием Reset платы )
Во-вторых, нам нужно соединить плату STM32 и терминал в компе, чтобы посылать на терминал строчку Hello World. Для этого соединим пин PB6 платы и пин Rx адаптера UART — USB, а также свяжем их «земляные» контакты. Почему именно этот пин? Забегая вперед — именно его нам выдаст Куб когда мы будем настраивать UART. Схема соединений:
|
|
UART ST32 2 Rx --------- PB6 (Tx) 4 GND ------------ GND |
Подключаем кабелем адаптер ко второму разъему USB, Линукс увидит его как устройство /dev/ttyUSB0. К этому устройству мы и подключаем терминал, как было показано выше.
Куб
Вот так с этими микроконтроллерами — столько возни из-за двух строчек кода. Запускаем Куб, и он первым делом потребует от нас указать, с каким микроконтроллером мы работаем. Если вы не ошиблись с заказом на Ali Express, то смело указывайте STM32F103C8Tx, в противном случае берите лупу и читайте обозначение на корпусе чипа. Далее быстро вспоминаем, какие две вещи мы должны проделать с конфигуратором.
Во первых, настройка коннектора JTAG. Открываем пункт SYS и устанавливаем Debug в состояние Serial Wire: это наш последовательный интерфейс связи платы с донглом St-Link V2.
Во-вторых, настраиваем UART: открываем USART1 и ставим Mode Asynchronous. Больше ничего делать не нужно. После этой манипуляции на вкладке Configuration появится кнопка USART1, где можно менять параметры порта. Заметим, что на схеме чипа появится метка у пина PB6: он будет назначен как передающий (Tx).
Каждый раз, когда в Кубе вы будете включать функцию, связанную с внешним миром, он будет задействовать пины (по своему усмотрению) и отмечать их зеленым цветом.
Вот в принципе и все. Заходим в Project/Settings, даем нашему проекту имя hardcore и в выпадающем меню Toolchain / IDE выбираем Makefile, как и договаривались — никаких IDE!
Единственное, что осталось, это сконфигурировать пин для мигания светодиодом. На моей плате светодиод уже разведен на пин PC13, поэтому кликаем на этот пин на изображении в Кубе и выбираем GPIO_Output. Если вы решите подключить светодиод к произвольному пину, точно также выберите его, только смотрите чтобы назначение не конфликтовало с другими пинами (Куб следит за этим). Не забудьте только токоограничивающий резистор и соблюдать правильную полярность.
Нажимаем на кнопку с шестеренкой, и наш проект готов: он появится в папке hardcore по тому маршруту, который вы указали в настройках.
Исходные файлы созданы, это вполне рабочий проект. Мы можем запустить make из директории hardcore, после этого исходники откомпилируются, скомпонуются и во вновь созданном каталоге build появятся исполнительные файлы hardcore.elf и hardcore.bin. Файл bin — это прошивка контроллера, файл в elf формате это исполнительный формат Linux. Конечно, исполнять его никто нигде не собирается — он нужен лишь постольку, поскольку в нем содержится отладочная информация: нумерация строк кода, имена переменных, функций и так далее. Нюанс: на самом деле собирается hardcore.elf, а потом уже из него утилитой objcopy извлекается прошивка hardcore.bin, избавляя последнюю от всего лишнего.
Та часть структуры проекта, которая представляет для нас интерес, лежит в каталогах Src/ и Inc/. Остальное трогать не нужно. Куб рассматривает созданное им дерево файлов и каталогов как свою безраздельную собственность, поскольку ему добавлять или удалять куски файлов в зависимости от того, как мы будем менять конфигурацию проекта. Он милостиво разрешает нам писать свой код в места обозначенные как /* USER CODE BEGIN */ и гарантирует, что трогать их не будет. Поэтому запускаем vim, открываем Src/main.c и ищем такой кусок в районе while(1).
Vim
Наверное несколько странно что после инициализации железа программа в main.c входит в бесконечный цикл ) А чего вы ждали, операционной системы нет, соответственно нет планировщика, и чем будет заниматься контроллер в холостом режиме — полностью наша забота. Поэтому после while(1), строго не выходя за рамки установленные нам Кубом, вставляем строчки кода таким образом:
|
|
/* USER CODE BEGIN WHILE */ while (1) { HAL_GPIO_TogglePin(GPIOC, GPIO_PIN_13); HAL_Delay(500); /* USER CODE END WHILE */ /* USER CODE BEGIN 3 */ } |
Первая строчка будет переключать светодиод, вторая — создавать задержку между переключениями в полсекунды, итого светодиод будет мигать с частотой раз в секунду.
Поскольку помимо помигивания светодиодом мы решили выводить настоящую текстовую строку, сделаем это командой
|
|
HAL_UART_Transmit(&huart1, (uint8_t*)"Hello World\r\n", 13, 0xFFFF); |
где 13 — длина нашей строки, подсчитанная вручную (вот ведь, всплыла чертова дюжина).
Команду можно вбить перед задержкой.
Когда выше я сказал, что можно запустить make, я несколько слукавил. Makefile для работы не хватает информации о том, где расположены все инструменты для сборки — toolchain. Обычно для этого задают переменную окружения GCC_PATH, но у меня на машине несколько разных компиляторов, поэтому я указал эту переменную в самом Makefile. Выглядит это так:
|
|
GCC_PATH = /opt/arm-none-eabi/bin |
Ваши инструменты могут быть в другом месте, у меня они находятся под каталогом /opt.
Теперь запускаем make, и наша прошивка готова. Результаты работы — объектные и исполняемые файлы создаются в каталоге build.
Прошивка микроконтроллера STM32
Надеюсь, к этому моменту вы осилили соединение донгла St-Link V2 и платы микроконтроллера. Вставляем St-Link V2 в usb и начинаем прошивку.
Прошивать будем из командной строки. Если вы в папке hardcore, запускайте команду:
|
|
$ st-flash write build/hardcore.bin 0x8000000 |
программатор выведет на экран результаты своей работы и если все нормально, завершит торжествующей фразой jolly good.
Признаком хорошего тона будет выполнять прошивку по команде make install. Для этого добавим в конец Makefile пару строк:
|
|
install: st-flash write $(BUILD_DIR)/$(TARGET).bin 0x8000000 |
Внимание: перед st-flash должна быть табуляция а не пробелы! make весьма строго относится к этому, и если вы напутаете это может быть источником трудно распознаваемой ошибки.
Теперь процесс прошивки будет выглядеть как make install. Со временем вы можете сами дополнить Makefile, чтобы по одной этой команде также выполнялась сборка.
Очистка всего проекта с удалением каталога build выполняется соотвествующей командой make clean.
Запуск
После прошивки микроконтроллер запускается (если он притормозил, дайте пинка кнопкой reset на плате), и наблюдайте мигающий светодиод.
Дальше, если вы не накосячили с подключением UART, после подключения адаптера вы увидите устройство /dev/ttyUSB0. Usb теперь стало стандартным последовательным устройством unix, поэтому с ним можно работать с терминальной программой. Запускаем ее:
|
|
$ minicom -D /dev/ttyUSB0 |
Настройки терминала менять не нужно. Значение скорости 115200 по умолчанию подходит, также подходят установки количества бит и признака четности.
Если все сделано правильно, адаптер будет подмигивать на каждую передаваемую строку, а на экране вы увидите строчки «Hello World» каждую секунду.
На самом деле, вы сделали большой шаг к тому чтобы с комфортом работать с микроконтроллером, поскольку теперь у вас появилась возможность выводить в окно то что происходит внутри.
Отладка
До сих пор поклонники IDE наблюдали за нами со сжатыми зубами, дожидаясь момента когда нам надо будет отлаживать программу. Вот тут они и выкинут свой главный козырь: а где подсветка строки, точки останова, отображение переменных? На самом деле, в реальной жизни, все это гораздо проще реализуется из командной строки. Перед глазами нет ничего лишнего, а только то на чем необходимо сконцентрировать внимание.
Перед тем как двинуться дальше, сделаем небольшой экскурс в кроссплатформенную отладку. Если вы пользовались знаменитым отладчиком gdb на своей станции, то скорее всего для вас было само собой разумеющимся то, что результаты отладки и само исполнение программы происходит на одной и той же машине. Однако, в общем случае это не так. Для нашей кроссплатформенной системы мы запускаем отладчик на своей PC Ubuntu, а программа работает на микроконтроллере STM32. Как все это должно быть состыковано вместе?
Все это уже предусмотрено в gdb. Мы даже не подозреваем о том, насколько это мощное приложение. В нашем случае мы будем использовать возможности работы отладчика в режиме клиент — сервер. Клиент — это приложение gdb на нашей машине, а сервер… занавес открывается… в качестве сервера будет выступать наш донгл St-Link V2. Не забываем о том, что помимо программатора это также gdb — сервер!
Принцип отладки выглядит следующим образом. Донгл St-Link V2 работает с платой микроконтроллера по интерфейсу JTAG и имеет возможность запускать и останавливать исполнение программы аппаратным способом. Все таки будет приятно знать, что когда мы соединяли его проводками, мы получили не только программатор но еще оказывается и отладку! С другой стороны, gdb сервер донгла запускается утилитой st-util и начинает прослушивать порт 4242 на нашей машине (значение порта по умолчанию можно поменять в командной строке). Мы со своей стороны запускаем отладчик gdb также на нашей машине, и указываем ему приконнектиться к gdb серверу донгла. С этого момента запущенный нами gdb становится клиентом, и все команды которые мы будем вводить в командной строке, будут исполняться St-Link V2.
До этого момента для краткости изложения я говорил про приложение gdb, но на самом деле конечно же мы используем не родной отладчик Ubuntu, а кроссплатформенный отладчик который идет в составе toolchain:
|
|
/opt/arm-none-eabi/bin/arm-none-eabi-gdb |
Общий принцип теперь ясен, переходим к деталям. Чтобы не плодить консоли, запускаем gdb сервер донгла St-Link V2 в фоновом режиме:
Запускаем в этой же консоли кроссплатформенный отладчик
|
|
$ /opt/arm-none-eabi/bin/arm-none-eabi-gdb |
или просто arm-none-eabi-gdb, если вы включили маршрут /opt/arm-none-eabi/bin в переменную окружения PATH. Отладчик выводит приглашение (gdb) и переходит в интерактивный режим.
Первым делом цепляемся к gdb-серверу донгла:
|
|
(gdb) target remote localhost:4242 |
С этого момента появляется возможность задать специальные команды для сервера через ключевое слово monitor; первое что сделаем — это сбросим и остановим микроконтроллер:
Сразу замечу, что с помощью команды monitor можно также выполнить прошивку, но мы этого делать не будем, потому что уже используем более понятный способ. Далее, загружаем отладочную информацию:
|
|
(gdb) file build/hardcore.elf |
Чтобы не вводить эти команды каждый раз при запуске отладчика, поместите их в файл debug.txt и запускайте в командной строке
|
|
$ /opt/arm-none-eabi/bin/arm-none-eabi-gdb -x debug.txt |
Подчеркну еще раз, как мы используем elf и bin файлы в кроссплатформенной отладке: bin файл не нужен отладчику, поскольку он уже прошит в контроллере. Из elf файла ему нужна только отладочная информация, код из elf — файла не запускается.
После того как мы подключились к gdb серверу, отладка идет в обычном режиме. Ставим точку останова на функции main() и запускаем на выполнение:
Точку останова можно поставить и на номер строки (включите отображение номеров строк в vim).
Осмотримся:
Продолжим выполнение в пошаговом режиме:
или в полном написании next. Если мы хотим зайти в функцию, вместо next используем step. Чтобы выйти из функции не дожидаясь пошагового выполнения, задаем finish.
Краткая памятка команд отладчика:
|
|
break: ставим точку останова на функцию или строку next: пошагово, не заходя в функции step: пошагово, заходим в каждую функцию по дороге finish: выходим из функции с выполнением оставшегося кода continue: идем пока не встретится точка останова until: идем до номера строки backtrace: смотрим, как мы здесь оказались: что было до этого list: смотрим исходник там, где остановились |
Если вы что-то подзабыли, смело просите о помощи, например так:
и отладчик скажет, что команда watch EXPRESSION обеспечивает остановку программы если значение выражения EXPRESSION поменяется. В отладчике очень много таких полезных фишек, пользуйтесь ими!
И последнее. Запускайте отладчик с ключом -tui чтобы сразу видеть на экране исходник своей программы. И больше вам не нужны никакие IDE ) Более того, сейчас вы точно представляете себе, как все эти куски взаимодействуют вместе. Иначе все тонкости реализации были скрыты за фасадом какого-нибудь тормознутого Eclipse.
Успехов в ваших начинаниях!
|
|


Last comments