|
|
… одетый только в халат из холщовой ткани, ходил в кабачки и к певичкам. Когда его спрашивали, почему он таков, он каждый раз открывал рот, засовывал туда кулак и не говорил. Император Лян-цзун призвал его и спросил: «Каков принцип Вашего Пути?» Гуйчжэнь ответил: «Одежда тонка — поэтому люблю вино, выпью вина и защищусь от холода, напишу картину — и расплачусь за вино. Кроме этого, ничего не умею». Лян-цзун не нашелся, что сказать…
От игрушек детства мы движемся к другим. Здесь — об этом.
Алхимия игры включает несколько ингредиентов.
Рецептура состоит из Миров, по которым можно путешествовать; не все из них достаточно хорошо населены. Дело — это Игрушка одного из миров.
Объединяя видимые и сокрытые элементы, Алхимия выступает и как самостоятельный Игрок.
Понимаю, тема несколько выбивается из ряда… но разнообразие прекрасно, полезно и бодрит, поэтому продолжаем. В последние два с половиной года я был сильно погружен коммерческую разработку на C++ , мой стол набитый комплектацией простаивал без дела, и вот пришло время размяться на аналоговом поле.
На самом деле микрофонный усилитель — это не просто так, а часть моего проекта, который я завершу — когда нибудь, надеюсь. Задача усилителя — завести голос с микрофона гарнитуры на АЦП STM32. Определенное время я развлекался, знакомясь с ужасными схемотехническими решениями, которые кочуют с сайта на сайт (высокоимпедансный микрофон на вход схемы с общим эмиттером), и решил дать простое решение с подробными разъяснениями (фокус с последующим разоблачением).
Итак, смотрим чертеж.
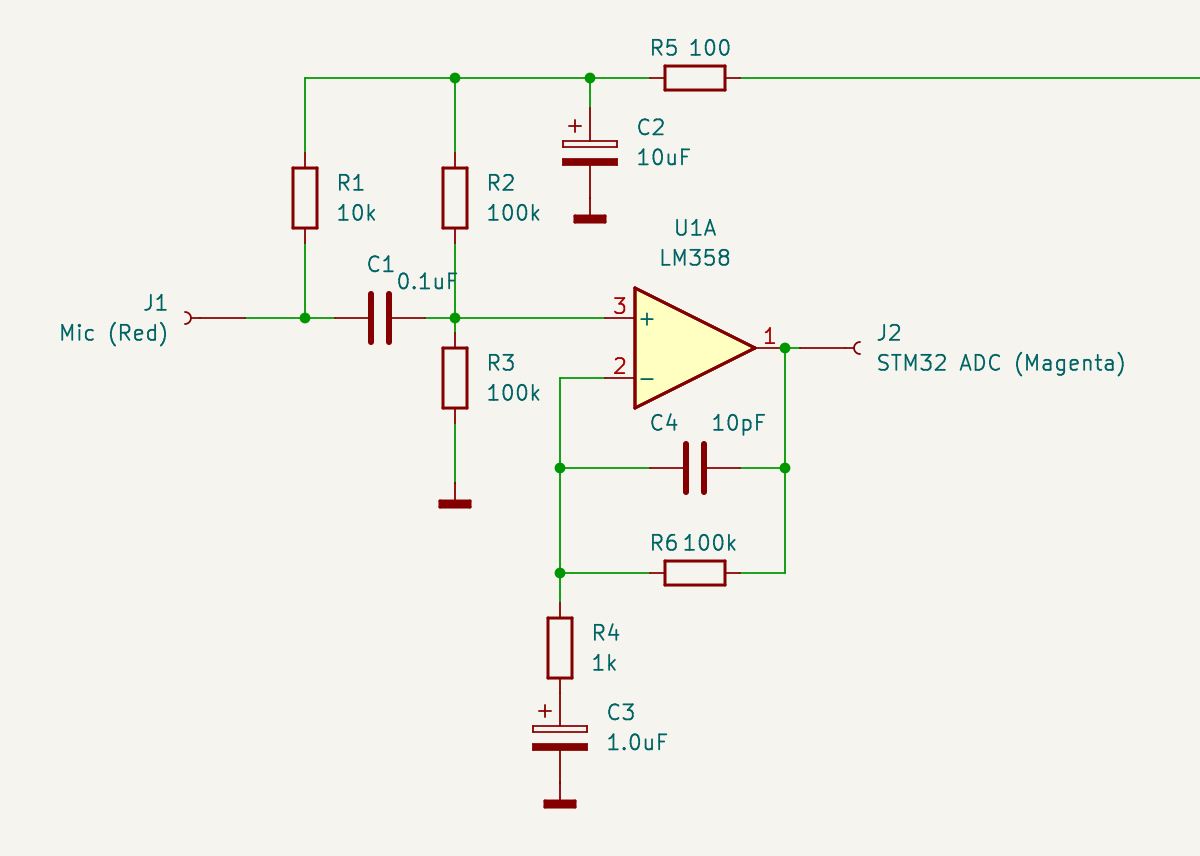 Микрофонный усилитель на LM358 / Microphone amplifier LM358 Слева подключаем микрофон, справа подаем выход усилителя на АЦП микроконтроллера. Пусть обозначения цветов вас не смущают — это маркировка проводов в моем монтаже.
Начинаем с микрофона. В гарнитуре он или электретный, или конденсаторный. И в том и другом случае на него нужно подать питание, что делает резистор R1, обеспечивая положительное смещение. Также и в том и другом случае микрофон имеет высокий импеданс, поэтому нагрузочный каскад должен иметь высокое входное сопротивление. Ходят легенды, что в микрофоны встраивают полевой транзистор, который обеспечивает высокоомную нагрузку для него — благо что питание подавать все равно надо. Я специально разобрал такой один, но транзистор вероятно был настолько мал, что я его не нашел даже под лупой.
Поэтому пусть будет универсальное решение — вход нашего усилителя будет высокоомным, поэтому подаем сигнал с микрофона на (+) вход операционного усилителя — ОУ. И давайте примем, что сопротивление входа (+) ОУ будет бесконечным, поэтому входную нагрузку будут определять параллельно включенные R2 и R3 (да — да, вы не ослышались — для сигнала что питание что земля все едино, поэтому микрофон получает нагрузку 50 кОм).
Лирическое отступление — почему на (+), а не на (-)? Ведь входы ОУ равноценны и образуют дифференциальный транзисторный каскад. Все дело в отрицательной обратной связи через R6, благодаря которой вход (+) становится высокоомным. Как это работает — рассказал на примере эмиттерного повторителя .
Давайте сразу про обратную связь. Она весьма двулична и ведет себя по-разному по постоянному и переменному току. По постоянному току играет R6 (и в этом варианте он вообще не нужен — мы могли бы накоротко замкнуть выход ОУ и вход (-)). Обратная связь получается 100 — процентной, поэтому коэффициент усиления каскада по постоянному току — единица, и средняя точка, которую устанавливает делитель R2/R3, будет такой же на выходе операционника, то есть — половина напряжения питания.
Теперь про обратную связь по переменному току. Здесь играет конденсатор C3, который закорачивает нижний конец резистора R4 на землю, в результате чего в цепи обратной связи появляется делитель R6/R4. Тут уже резистор R6 выполняет свою роль и совместно с R4 устанавливает коэффициент усиления каскада по переменному току, равный 100.
Конденсатор C4 давит усиление на высоких частотах, что лишает широкополосный LM358 возможности самовозбудиться на высоких частотах (вполне реальная перспектива, если фазовый сдвиг в цепи обратной связи получится другим нежели чем 180).
Поскольку режимы по постоянному току для микрофона и входа (+) ОУ — разные, изолируем эти цепи конденсатором C1. Надеюсь, не надо объяснять, что он проницаем для входного сигнала, и неожиданно маленькая емкость — 0.1 мкф совсем не большое препятствие, потому что опять таки — вход высокоомный.
Как вы наверное догадались, линия в верхней части, уходящая вдаль направо — это питание 3.3 В. Столько я рассчитываю получить с USB смартфона (ну вот, проговорился про еще про один кусок будущего проекта).
Для LM358 такое напряжение — нормально. Заметим, что выходной сигнал будет меняться не относительно земли (разделительного конденсатора на выходе ОУ нет), а между землей и 3.3 В — что АЦП и надо.
Для чего нужна цепочка R5C2? Практикующие инженеры знают, что мусор в цепях питания — обычное дело. На чувствительном входе каскада ОУ он нам совсем не нужен, и поэтому фильтр R5C2 будет прибивать все что по частоте выше постоянного тока (в идеале).
Пара электролит — керамика для сброса мусора на землю также стоит в правой части, которая не видна. Зачем керамический конденсатор маленькой емкости в параллель с электролитическим? Последние имеют неприятное свойство — паразитную индуктивность. Поэтому с ростом частоты они будут не очень хорошим конденсатором.

На макетке операционник в левой части. Особо зоркие могут заприметить транзистор в правой части — не обращайте на нее внимание, это очередной кусок проекта (который надо полностью поменять).
В результате экспериментов выяснилось, что усилитель держит неплохую полосу от 100 Гц до 10 кГц и негромких песен вполне достаточно до раскачки выхода от 0.5 В до 2.5 В.
When using numpy at the beginning of a project we don’t think about performance. This is because it is more important for us to get solution that works. And only then, with real data, observing how our computer begins to slow down, we have to find answer on how to avoid this. And then we remember the GPU inside our computer and think: can it help us?
Yes, sure. PyTorch can utilize GPU and perform all computations on it. PyTorch uses Tensor primitives like numpy arrays. Unlike numpy, once declared tensors reside on GPU, and are calculated on it. Due to a lot of the parallel working GPU inits, computing performance arises dramatically.
We will take the matrix multiplication algorithm for the example.
First, let’s make sure the multiplication computations are performed correctly.
|
|
import numpy as np a = np.array([[1,2],[3,4]]) b = np.array([[5,6],[7,8]]) print(a @ b) |
Output:
Everything is as expected.
Now, tensor comes into play. At this point, all the necessary modules and drivers have already been installed:
|
|
import torch print("Cuda is available" if torch.cuda.is_available() else "Cpu only available" ) |
Output:
Let’s allow PyTorch to multiply matricies:
|
|
ta = torch.from_numpy(a) tb = torch.from_numpy(b) print(torch.matmul(ta, tb)) |
Output:
|
|
tensor([[19, 22], [43, 50]]) |
The result is the same as for the numpy.
Take a larger matrices and see how much time it takes to calculate in each of the three modes:
1) PyTorch in «cpu» (numpy — like) CPU only mode
2) PyTorch in «cuda» (GPU) mode
3) Numpy CPU mode
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import datetime as dt dtype = torch.float M = 100 def calc(device): a = torch.rand(M, M, device=device, dtype=dtype) b = torch.rand(M, M, device=device, dtype=dtype) n1=dt.datetime.now() torch.matmul(a, b).size() n2=dt.datetime.now() print(device, '\t', M, n2-n1) a = np.random.rand(M, M).astype('f') b = np.random.rand(M, M).astype('f') n1=dt.datetime.now() np.matmul(a, b).size n2=dt.datetime.now() print("numpy", '\t', M, n2-n1) calc(torch.device("cpu")) calc(torch.device("cuda")) |
Output for M=100
|
|
numpy 100 0:00:00.000190 cpu 100 0:00:00.006382 cuda 100 0:00:00.017093 |
Output for M=1000
|
|
numpy 1000 0:00:00.014212 cpu 1000 0:00:00.064719 cuda 1000 0:00:00.014513 |
Output for M=10000
|
|
numpy 10000 0:00:12.415283 cpu 10000 0:00:12.241426 cuda 10000 0:00:00.036787 |
For small matrices (M=100) numpy looks like a performance champion. Even torch in cpu mode loses to it. The worst results are observed for the GPU.
For a medium-sized matrices (M=1000) the results are leveled out. Numpy and torch in cpu mode are the same and only torch in gpu mode is far behind.
At the moment, everything looks sad for GPU. It makes a real breakthrough for large-sized (M=10000) matrices. Here the gap in execution speed is huge: 37 milliseconds for GPU versus 12 seconds for numpy.
Simultaneous computing is good
Когда люди начали создавать компьютеры, сравнение с аналогичной продукцией живой природы не заставило себя ждать. Все (за редким исключением) сошлись во мнении, что нейросистемы животных слишком сложны и медленны, чтобы быть достойными более глубокого изучения. Здесь под изучением я подразумеваю не биохимический анализ нейронов, а понимание уровня системы: по каким алгоритмам она работает и самое главное — почему было сделано именно так.
Печально, но на вопрос «почему так» судя по всему отвечать некому. Подробно об этом написано в замечательной книге Доккинза «Слепой часовщик», а если коротко — то не было никакого Главного конструктора, который создавал живые организмы в тиши своего кабинета. Эволюция за сотни миллионов лет сама сделала эту работу, непрерывно экспериментируя с мутациями, оставляя жизнеспособные решения и безжалостно уничтожая ошибочные. Нам осталось строить предположения, наблюдая конечный результат.
Читать дальше…
По сравнению с такими шустрыми средствами, как противорадиолокационные ракеты (Anti Radar Missile) беспилотник выглядит сущим недоразумением. Однако, это всего лишь следствие инерции мышления, когда на самом деле главный недостаток БЛА по сравнению с ракетой — низкая скорость, становится преимуществом в следующих случаях:
нужно хорошенько рассмотреть цель; можно позволить себе прогуляться для того чтобы выбрать что-либо
Читать дальше
Множество психотехник проникает в нашу жизнь. Одна из них — визуализация желательных событий. Утверждается, что представляя объект своих устремлений в виде образа — мысленно, или в звуках или хотя бы на бумаге — вы рано или поздно его получите. Наконец найден волшебный эликсир для диванной армии вершителей реальности: не затрачивая времени и сил, сберегая нервы
Читать дальше
В статье маркеры визуальной системы автоматической посадки БЛА была описана обработка видео-данных реального времени для системы оптического типа — VBLS. Это была хоть и шустрая, сделанная на C++, но модель. Теперь, как было замечено в конце этой статьи, пришло время показать систему в боевом варианте, где обработка видеопотока параллелится в ПЛИС.
В данной системе для
Читать дальше
Визуальная автоматическая посадка БЛА может выполняться не только по характерным точкам местности, но и по специально подготовленным и известным изображениям — маркерам. Собственно сама стандартная разметка ВПП состоит из таких маркеров, только исторически они предназначались не для обработки компьютером, а для человека — пилота. Поэтому нет ничего удивительного в том, что искусственный интеллект дрона потребует
Читать дальше
Эта история конечно имеет свои универсальные черты. Это означает, что разработка любой отечественной военной техники, не попадающей под непосредственное внимание первых лиц, идет примерно схожим образом. С другой стороны, в каждом проекте есть свои, отличающиеся от других особенности, и поэтому каждый волен выбирать, как ему воспринять эту историю: еще раз убедиться в том, как она
Читать дальше
В предыдущей статье я рассказывал о том, как хорошо работать с микроконтроллерами STM32 без операционной системы. Однако может наступить момент, когда вам понадобится наладить взаимодействие с вашим МК по сети. Например, что-нибудь типа умного дома или передача отладочной и диагностической информации на web страницу. Наличие Ethernet интерфейса — это конечно сильный аргумент для того, чтобы
Читать дальше
Возможно, вы очень хотели заняться чем-нибудь, что связано с чипами, прошивками, возможно даже использовать новые знания для домашних поделок — мало ли вещей, которые можно автоматизировать, начиная от контроллера солнечной батареи и заканчивая автоматом запуска бензоагрегата? При этом, не сильно погружаясь в особенности операционных систем Linux / Windows и не используя сильно избыточные платы, такие
Читать дальше
|
|

Last comments