
Когда мы работаем с информацией, нам хочется докопаться до самой сути и отбросить второстепенные детали. Этот процесс неизбежно связан с потерями информации, которая не представляет интереса, и одновременно с попыткой сохранить значимую информацию. Так например работают все алгоритмы со сжатием аудио и видео: оставляя ту часть сигнала которая является существенной для нашего уха и глаза, они отбрасывают второстепенные детали.
В примере с дядюшкой Ляо мы использовали метод главных компонент PCA, чтобы абстрагироваться от нетвердой походки нашего персонажа и попытаться выяснить главное: куда собственно он направляется. Это конечно не единственный метод удаления избыточной информации: в области нейроподобных сетей сходную функцию несут такие интересные устройства, как автокодеры (Autoencoder).
В отечественных статьях их часто называют автоэнкодерами, что не совсем корректно: английское выражение encoder это просто кодер, или устройство которое кодирует информацию. Название крайне неудачное, поскольку кодирование — слишком общий процесс, который в данном случае ни о чем не говорит.
Бутылочное горлышко
Автокодер — это нейронная сеть, которая выглядит следующим образом. Слева как обычно подаются входные данные, справа — выход сети. Соответственно, присутствует входной слой (input layer) и выходной слой (output layer). Размерность выходного слоя точно такая же как и входного. Внутренние слои, которые по традиции называют скрытыми — hidden layers (вот еще одно название, сбивающее с толку) представлены всего одним слоем.
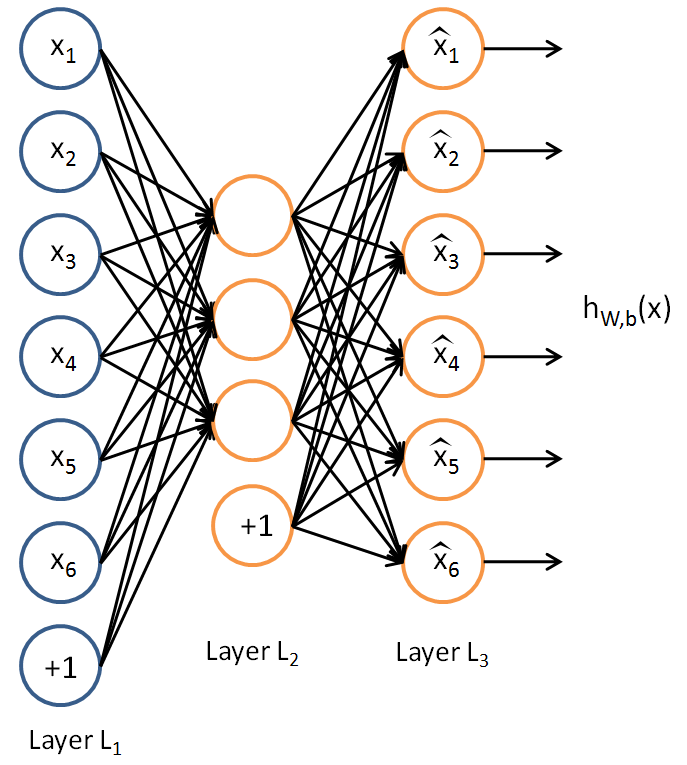
Нейронный автокодер / Neural Autoencoder Layer L1: входной слой Layer L2: скрытый слой Layer L3: выходной слой
Принципиальной особенностью автокодера является то, что при совпадении размерности входного и выходного сигнала скрытый слой имеет низкую размерность. Возникает узкое «бутылочное горлышко», которое ухудшает информационную емкость канала от входа к выходу, и мы вправе заподозрить, что это ухудшение будет сопряжено с потерей информации.
Так оно и есть, информация теряется, но разве не этого мы хотели? Отбросить лишнее и сосредоточиться на существенном. Осталось решить один простенький вопрос: как это сделать.
Есть и другие реализации нейронных автокодеров, соблюдающие тот же принцип бутылочного горлышка: например, размерность промежуточного слоя может быть большой, но при этом он выполняется разреженным, слабо связанным со входным и выходным слоями.
Есть что терять
Таким образом, автокодеру есть что терять, и чтобы очистить входной сигнал (изображение например) от несущественных деталей с одной стороны, и не расплескав донести существенные части до выхода — с другой, нужно подсказать автокодеру как это делать. Как это принято в мире нейронных структур, да и человеческого общества, это происходит с помощью обучения. Натаскивая нейронную сеть на разные виды изображений, ее весовые коэффициенты модифицируются таким образом, чтобы оставить только ключевую, существенную информацию на выходе.
Говоря другими словами, автокодер сжимает входную информацию, исходя из своего представления о том, что главное и второстепенное в этой информации.
Для того чтобы наш нейронный автокодер вел себя осмысленно, входной тренировочный набор должен быть под определенными ограничениями. Если мы будем тренировать его например на белом шуме, ни о каких существенных и второстепенных данных говорить не приходится. В этой замечательной статье, из которой кстати я позаимствовал рисунки, для тренировки автокодера использовалось следующее ограничение по входным данным:

Под входными данными понимается квадратик изображения размером 10х10 пикселей, при этом интенсивность каждого пикселя может меняться.
Попробуем вникнуть в суть этой сухой формулы, что мы собственно считаем главным во входном сигнале. Сумма квадратов и инженерном мозгу начинает сразу ассоциироваться с энергией. Так видимо и есть; на вход подаются тренировочные последовательности изображений, яркость которых (сумма значений каждого пикселя) не должна превышать единицы.
Это очень общее ограничение, которое позволяет делать любые допущения относительно связности и формы изображений: это может быть как бледная спираль, так и одинокий ярко и гордо светящийся пиксель, при этом спираль можно раскинуть по всему изображению: главное чтобы она не светила слишком ярко. Если копнуть немного глубже, то спирали во входных данных скорее всего не получится, поскольку набор дополнительно подвергался «отбеливанию», т.е. ослаблением корреляционных связей между соседними пикселями, что делало тестовые данные более случайными.
Поскольку по замыслу автокодер должен повторить на выходе то же самое, что подали на его вход (с некоторой степенью приближения конечно), будет интересно, как он будет изворачиваться с учетом бутылочного горлышка и насколько будут упрощены, или сжаты входные изображения.
Неслучайное в случайном
Вот тут и наступает самый интересный момент. На рисунке ниже (позаимствованном из той же замечательной статьи) показано, какие закономерности увидел автокодер во входных данных.

Результат работы нейронного автокодера
Не знаю, как у вас, но у меня это вызывает ассоциацию создания некоего порядка из хаоса. Как будто ты присутствуешь при рождении первоэлементов, из которых потом будет построена вся вселенная ?
Чему же научился наш Autoencoder? На рисунке видно, как он выделяет границы освещенности исходя из самых разных положений. При этом шумовая, или «отбеленная» информация подавлена: мы совершенно четко видим регулярные структуры, которые могут в дальнейшем использоваться для распознавания объектов или сигналов. Из-за ограниченной размерности скрытого слоя, или бутылочного горлышка автокодер вынужден упрощать входные данные; а путь к упрощению только один: найти закономерности, которые позволяют хранить данные об этих закономерностях в сжатом виде в структуре самого автокодера.
Подобные нейроподобные алгоритмы открывают второе дыхание для хорошо известных задач, таких как распознавание изображений, распознавание речи, поиск скрытых закономерностей в данных, сжатие данных на основе предварительного обучения. Только для этого вначале нужно решить задачи по преодолению существующего технологического барьера: выйти на другой уровень технологии, основанный на цифровой или аналоговой параллельной обработке.
Ответить